 "Slipstream" is a series of posts where I would like the reader to find guidance about machine learning topics applied to investments such as data pre-processing, EDA, ML models, strategy backtesting and other ML-related areas. My examples and coding snippets will be as short and sweet as possible in order to convey the key idea instead of providing a lengthy code with poor readability that damages the purpose of the post. Machine Learning models training can be a tedious task. Unless we have real time needs to train our model - i..e. high frequency trading or short term investment horizon strategies - the best way to be productive is to train the model once, save it and upload later when needed most for tasks such as comparing against other model or simply predict new results using newly released predictors's data e.g. earnings data. Moreover, we may consider using the same model results in another project/strategy. Hence, saving a trained model and upload it at our convenience will deliver significant time savings in our production pipeline. These "saving" and "loading" processes are also known as serialization and deserialization The good news is that Python allows multiple approaches to carry out serialization and deserialization of our ML models: pickle module, joblib module and proprietary development. A quick comparison overview is provided in the next table with apparent trade-offs between flexibility and complexity when comparing pickle and joblib against a more in-house/proprietary development approach. 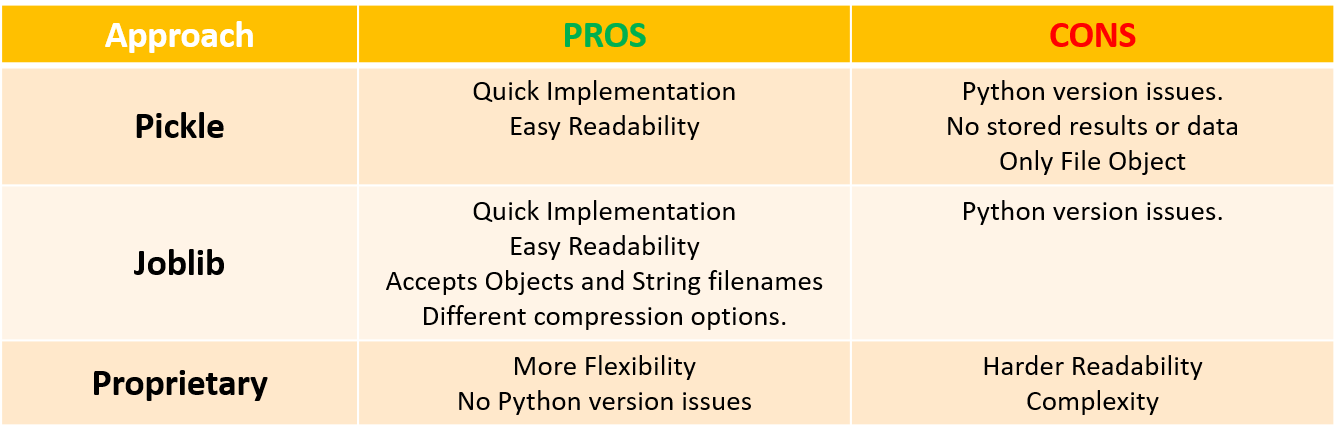 For illustration purposes, a simple ML model is created without accounting for hyperparameter optimization, cross-validation or data pre-processing. The objective of this post is to understand how to save a model - no matter how complex or simple - so the next few lines of script will suffice. Ideally, we shall do some hyperparameter optimization and cross-validation, yet we'll leave data for another posts aim at optimizing algos. Data gathering is the first stage. Imagine our objective is to develop a model to predict daily moves of Coca Cola (Ticker: KO) so we use pandas_datareader module to download the security price information. In addition we will create several predictors for our model based on simple moving averages as well as return lags. Next step is to split the data between "train" and "validation", and use the train indices to define our training sample. Last but not least, we run a simple logit model in order to have a ML model to play with. Code Editor
Code Editor
Now that our model is trained and ready so let's discuss our three approaches to save and load it in the future at our own leisure. Approach 1: Pickle Module The pickle module implements an algorithm based on binary protocols for pickling (serialization) a Python object structure into a byte stream, and unpickling (deserialization) a byte stream back into an object hierarchy. Pickle is easy to implement but it doesn't come without pitfalls such as difficulties dealing with large data, dependency on importing other libraries, lack of compression options and inability to store data (e.g. results, etc). 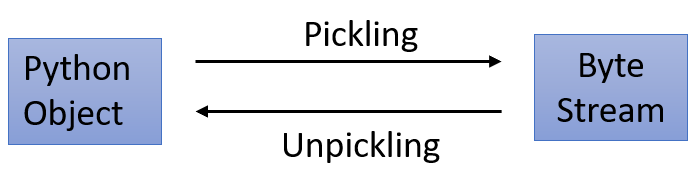 Firstly, we import the pickle library and define a variable to store a string with the name of the pkl file where the model is going to be serialized. The pickle.dump() allows us to save models in a desired location: Secondly, we will load back our model and confirm the logit model has been deserialized successfully: Output
Apparently the model loading is working since we obtain exactly the same results. We could have perform additional tests, yet for the sake of this post brevity this former test is enough. Approach 2: Joblib Module The joblib module is a buil-in method in the scikit-learn module that works better with large data. Joblib also saves the model in pickle format, yet code readability improves significantly as no other libraries are required to be imported plus it also allows to store data. Furthermore, Joblib works with both file objects and string filenames, whereas Pickle requires a file object as argument. Last but not least, Joblib offers a broader set of options when choosing compressing formats (gzip, zlib, bz2') and the degree of compression. The few lines below offer a simple implementation of joblib to initially save our model: Once again, we will check if the deserialization works by loading back: Our loaded model delivers the same result so no issues here either. As the snipped above shows, joblib allows to pass both file objects and names in string format comparing to Pickle's object-only syntax; which improves code readability when using joblib. Approach 3: Proprietary The possibility of building a ML model synthetic class to serialize and deserialize our models in JSON format allows to have full command upon which data needs to be stored and how besides having the possibility of opening the JSON file with any text editor to inspect visually. One caveat is code readability as syntax complexity increases as more flexibility is required. Another shortcoming is the use of the JSON format instead of a byte stream, which impacts negatively the security of our infrastructure. Last but not least, this approach requires continuous fixing if the ML researcher adds any new variables/predictors; besides sometimes sklearn ML models objects in Python might have different structures thus forcing the administrator to tweak the code below further. The script underneath shows how to build a class to accomplish this purpose. Firstly, observe our class "my_model" is built as child class inheriting the methods and attributes from our parent class i.e. "model" object. Once the new child class "my_model" is created, the user can call three methods:
Some explanations are provided in the next lines in order to clarify the enumerated lines of the script:
Before moving forward to the next section, we can test our class is behaving as expected: And our final acid test checking the score with training data: Other Approaches: Beyond the Local Horizon
This post is intended to help readers to make life easier saving and loading models for local machine learning experiments. Nevertheless, these approaches fall short when working with huge models or big data models plugged into production for corporate purposes. Luckily there are alternative ways to manage/store models non-locally using remote databases or cloud computing tools that allow us to save and load our ML models much more efficiently with some examples shown below:
The former approaches are more realistic in term of managing ML model pipelines, yet they are beyond the scope of this post. Future posts of the "slipstream" series will delve into more complex issues related to ML management. Recommended Resources:
0 Comments
Leave a Reply. |

Carlos Salas
LINKS Data Science & ML NYC Data Science Blog Data Science Central Towards Data Science Kaggle Blog Analytics Vidhya Quant Finance Quantocracy MoneyScience QuantStrat Trade R Investments Market Screner Macro Calendar Corporate Calendar Advisor Perspectives Trading Economics Portfolio Visualizer Datasets Opendata Data.Gov World Bank Quandl |
 RSS Feed
RSS Feed