 Neuromancer Blues" is a series of posts where I would like the reader to find guidance about overall data science topics such as data wrangling, database connectivity, applied mathematics and programming tips to boost code efficiency, readability and speed. My examples and coding snippets will be as short and sweet as possible in order to convey the key idea instead of providing a lengthy code with poor readability that damages the purpose of the post. The first part of these topic was dedicated to briefly explain the key differences between Threading and Multiprocessing besides focusing more on threading applications to boost our productivity when executing I/O-bound tasks. Because an image is worth a thousand words, the picture below illustrates neatly the key points for understanding these concepts courtesy of Corey Schafer 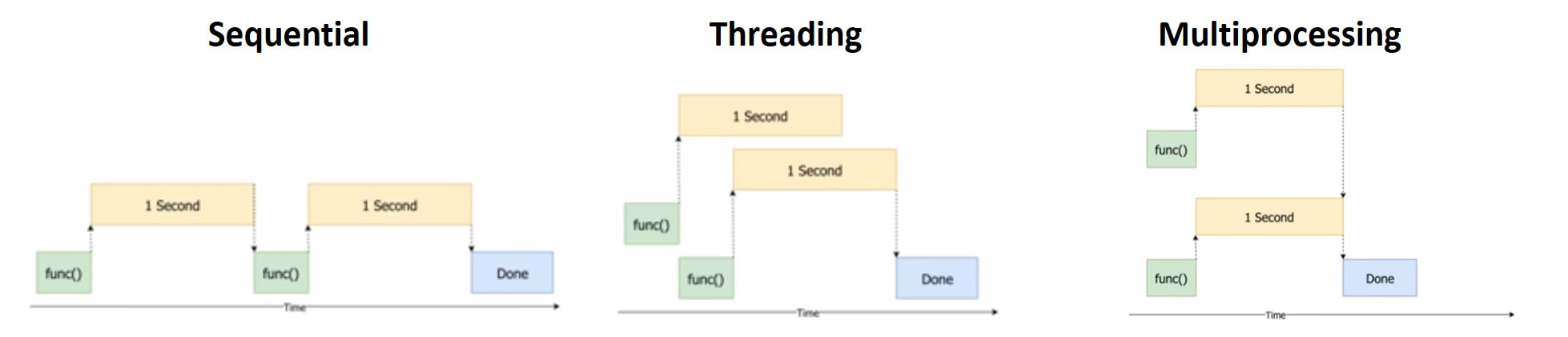 As highlighted in the first part of this series, multiprocessing is advised to be used for CPU-bound tasks as it allows the programmer to open multiple processors on a given CPU, each one of them with their own memory and with no GIL limitations. Another big difference between threading and multiprocessing lies in the former sharing global variables, whereas the latter's separate processes are completely separate i.e. one process cannot affect another's variables. Classic Approach: Using Multiprocessing Module The built-in multiprocessing module in Python is the simplest way to spawn multiple processes that run parallel to each other instead of concurrently as when we implement threading. This module allows the user very easily and intuitively to implement multiprocessing very similarly as when using the theading module. Bear in mind that although the coding experience is similar using both modules, very different things happen in the backstage as previously explained; with a big difference, being that threading shares global variables, whereas multiprocessing runs simultaneously separate processes with their own variables. Learning by doing is the best way to convey the aforementioned concepts so let's get down to business. Remember multiprocessing is meant to work better with CPU-bound tasks thus we will define a CPU-bound function that will train and deliver results from a naive machine learning model training based on SVM. Please beware we used the word "naive" for obvious reasons as we don't conduct data-pre-processing, feature selection, cross-validation or any kind of hyperparameter optimization since the purpose of this post is to focus on boosting our code efficiency using multiprocessing. Future posts in other series will focus on enhancing machine learning models applied to investments. Firstly, we proceed to store in an object some data that our CPU-bound task will need in order to perform the SVM model training. Code Editor
Secondly, the task is wrapped up in function cpu_task() with our naive SMV model training and delivery of model accuracy and accumulative return for each ticker that is passed as parameter. Note a time.sleep(3) line is included in order to simulate a more realistic and CPU-intensive task time completion. Now that we have our data and the task/worker function to be run for each one of our companies, let's review different multiprocessing approaches to conduct this analysis. As illustrated in Part 1 of this series, the next code snippet provides an idea about the efficiency of sequential execution i.e. run one task at a time with the next task only starting when the last task is complete. Code Editor
Output
Our CPU-task is taking approximately 5 second per ticker to be completed. Initially it does seem quick, yet bear in mind our aim is to make our program as scalable as possible. Currently it would take our program more than 40 minutes to conduct the same analysis for the whole S&P 500 universe so improvements are needed here: Enter the Multiprocessing module: Output
Multiprocessing implementation almost cuts in half the initial time it was taken to run our CPU-task when using the sequential approach. New users of the multiprocessing module probably require further description upon the lines highlighted with numerical comments:
Best thing about the Multiprocessing module is that it allows to work using "Pooling" mode and obtain significant readability gains in our script, avoid non-necessary looping and harvest some gains in time execution as well: Output
Once again, the syntax above might require further clarification for those non-familiar with this module:
New Approach: Process Pooling using Concurrent.Futures Module As reported in Part 1 of this series, The concurrent.futures module provides a more straightforward and readable way of conducting both threading and multiprocessing. This module is an abstraction layer on top of Python’s threading and multiprocessing modules that simplifies their use. Nonetheless, it should be noted that there's a trade-off between higher code simplicity and lower code flexibility. Hence, the user might be interested in using either Multiprocessing or Concurrent.Futures depending on the program complexity and requirements. See below the code for running our program using this new library: Output
This new approach performs a bit worse than our previous multiprocessing options, yet it still is significantly much quicker than the standard looping sequential choice. Several things need to be underlined with regards the use of either concurrent.futures or the native multiprocessing module:
To sum up, both Multiprocessing and Concurrent.futures module have similar performance, although the former provides more flexibility for custom tasks while sacrificing code readability. This is the same reading we obtained from comparing both modules for Threading purposes. 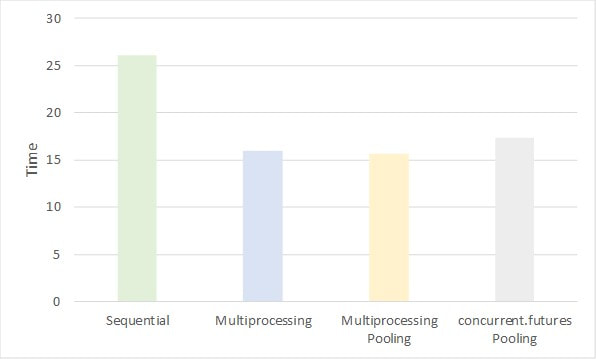 This has been a short introduction to both threading and multiprocessing with quite simple and short code script to convey the key idea.
My objective in future post of the Neuromancer series is to delve into programming efficiency topics, and other data science topics useful for investment purposes. Recommended Resources:
0 Comments
Leave a Reply. |

Carlos Salas
LINKS Data Science & ML NYC Data Science Blog Data Science Central Towards Data Science Kaggle Blog Analytics Vidhya Quant Finance Quantocracy MoneyScience QuantStrat Trade R Investments Market Screner Macro Calendar Corporate Calendar Advisor Perspectives Trading Economics Portfolio Visualizer Datasets Opendata Data.Gov World Bank Quandl |
 RSS Feed
RSS Feed